Update – January 2024: We recently partnered with peers at AWS to author a post on this same subject matter. Click here if you would like to read the AWS blog post.
The Problem: A Mad Rush to Centralize
Enterprise worldwide is scrambling to optimize data assets ahead of anticipated never-before-seen demand, driven by advances in large language models (LLMs).
Unsurprisingly, most organizations are laser-focused on pulling data assets into a central repository — blissfully unaware of their own “data selfishness” — and missing a prime opportunity to supercharge accessibility for teams, partners, and other stakeholders.
In addition to poor accessibility, there are other problems with centralized data hoarding and the endless loop of nuclear rewrites it invokes. For instance, as newer and more efficient data tools are invented, pressure to adopt bleeding-edge technology can lead to endless re-architecture and perpetual tech-debt.
Need we remind ourselves of why we have all this data in the first place? To work with it, of course — and to do that, what we need most are accessibility and availability.
The (Almost Perfect) Solution: Data Mesh
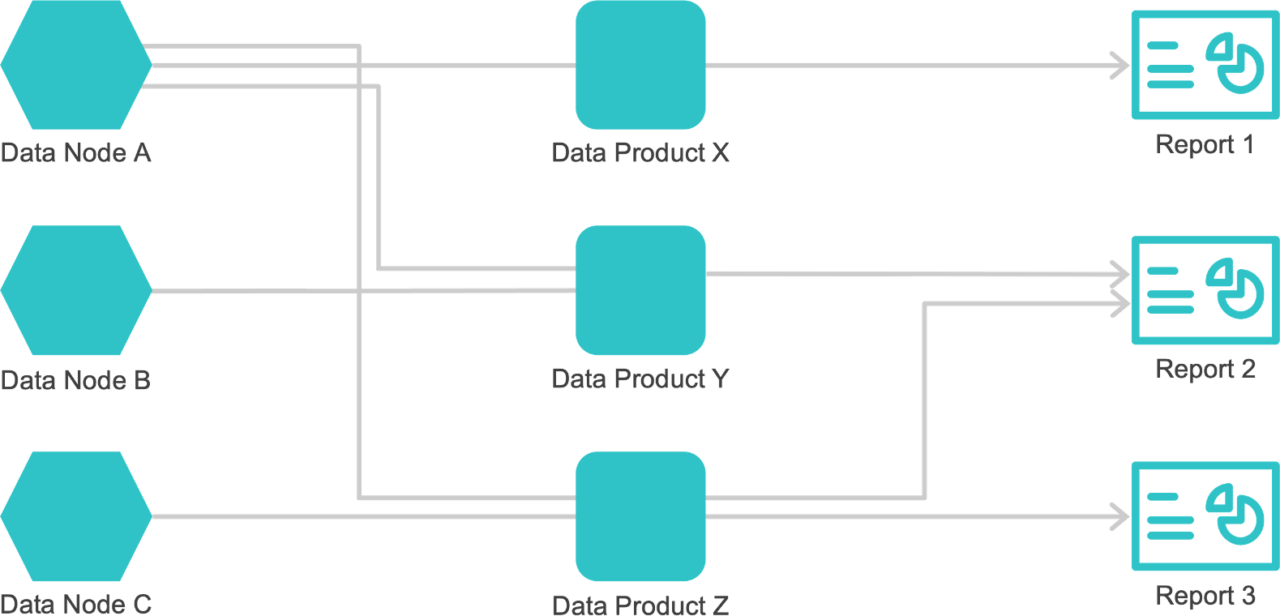
Introduced in 2021, the Data Mesh framework provides a more dexterous approach. With it, data is grouped into independent, focused data domains — without need for centralized management — thus, easing burden on one central team. By distributing ownership of various data amongst numerous teams, it’s served to stakeholders in a more flexible and accountable way.
Over the course of two years working with Data Mesh, we at Annalect realized that, not only could it unify data sets across our organization — but with some enhancements, it could also become an invaluable framework for data collaboration — not only internally, but with outside clients, vendors, and partners!
We discovered massive, untapped potential in this already powerful framework.
Here’s how we implemented Data Mesh, then made it even more dexterous and collaborative…
Data Mesh in Practice
As groundbreaking as the original Data Mesh paper was, those who’ve tried to use it as an implementation guide are challenged by its non-prescriptive nature.
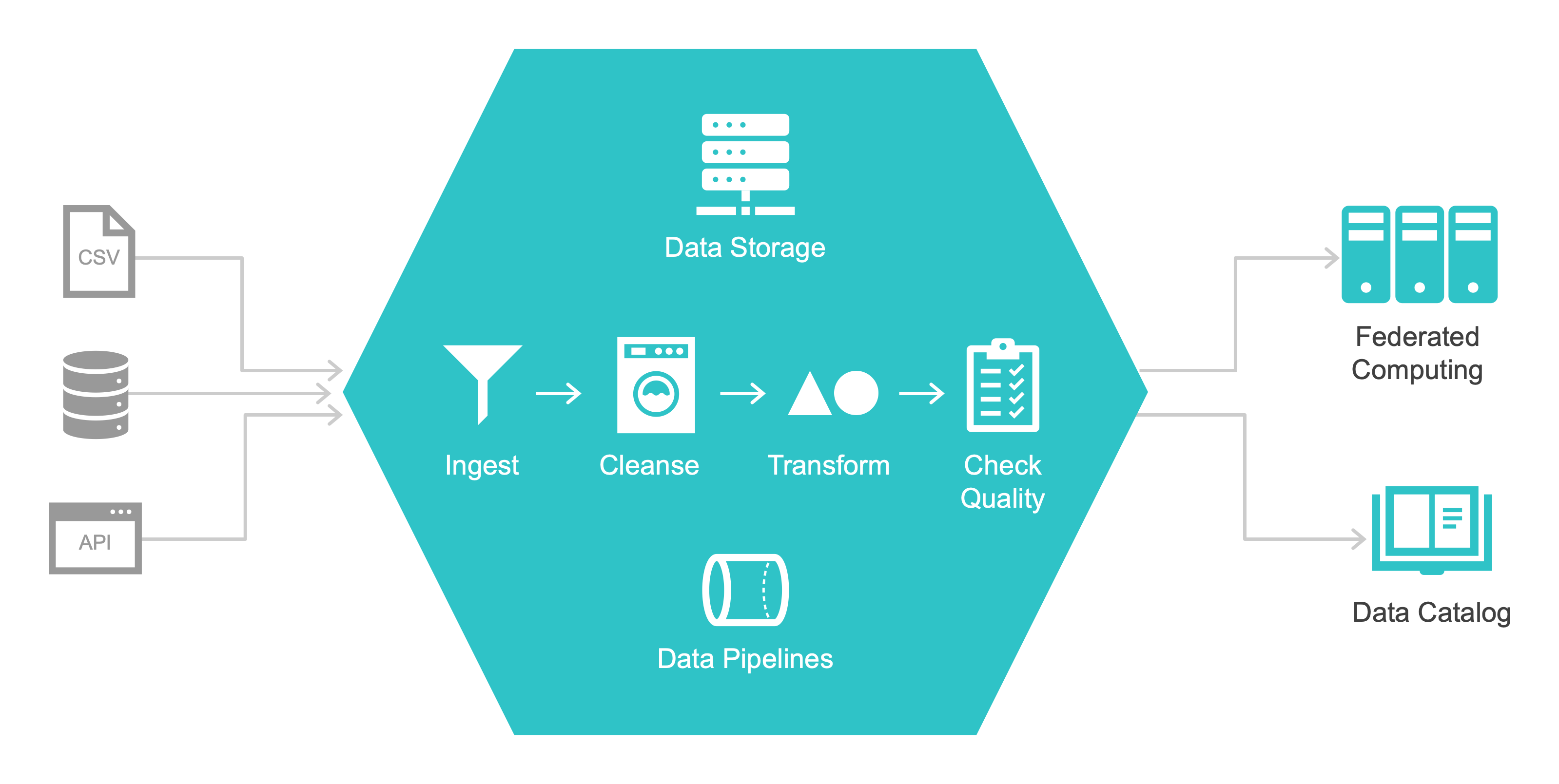
Crucially, we at Annalect carefully planned and mapped Data Domains, and believe this was a key part of our Data Mesh strategy. Our classification and categorization of data sets took weeks of collaboration, involving Product and Tech teams. We believe this was time well-spent. Remember — paper is cheap. Cataloging and classifying data sources is much easier than re-engineering it. We grouped data into domains by granularity: event (time stamped), audience (data with a person-id identifier), and creative asset (creative file ID).
While the main objective behind mesh-ifying was to locate all data sets across our organization — because we didn’t have to move them, we were able to keep intact their architecture and storage types — without requiring that they conform to a single standard.
Requirements were few: nodes must adhere to pre-determined governance standards, and publish details to a Data Catalog — making it available to data consumers.
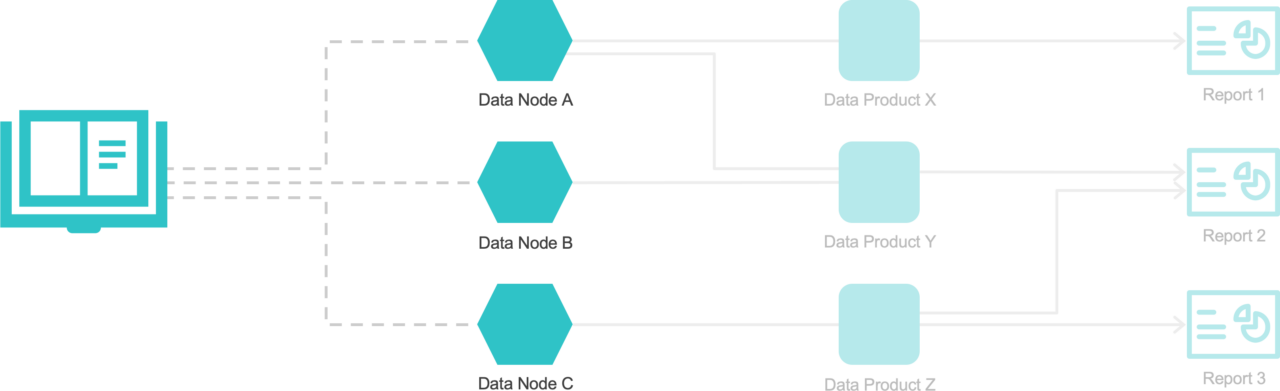
An easy-to-understand metaphor is that of a hotel: At Data Mesh Hotel, rooms aren’t required to have the same paint color or furniture. They can all be different styles, as long as they share the same key management, HVAC, and booking system.
Data nodes could even be “ronovated” if necessary, while keeping the local node architecture (data lake, data warehouse, storage with ETL pipelines), based on whatever made sense for that specific data type.
Incorporating New Tools: Clean Rooms & Distributed Compute
Data consumers generally don’t care about technicalities like how data is housed or whether it’s coming to them through a particular flavor of pipeline. What they do care about, is getting the data they need without waiting weeks for access, via their method of choice (dashboards, APIs, analytic workbenches, etc.).
To enhance Data Mesh’s inherent suitability for cross-team and cross-organization collaboration — getting data to a multi-disciplinary base of people who want it, where they want it — we incorporated some powerful new tools.
Enter Distributed Computing and Neutral Clean Rooms.
Distributed Compute separates storage from compute, and allows for one-point entry warehouse-like capabilities, without building an actual warehouse (check out Trino and Starburst).
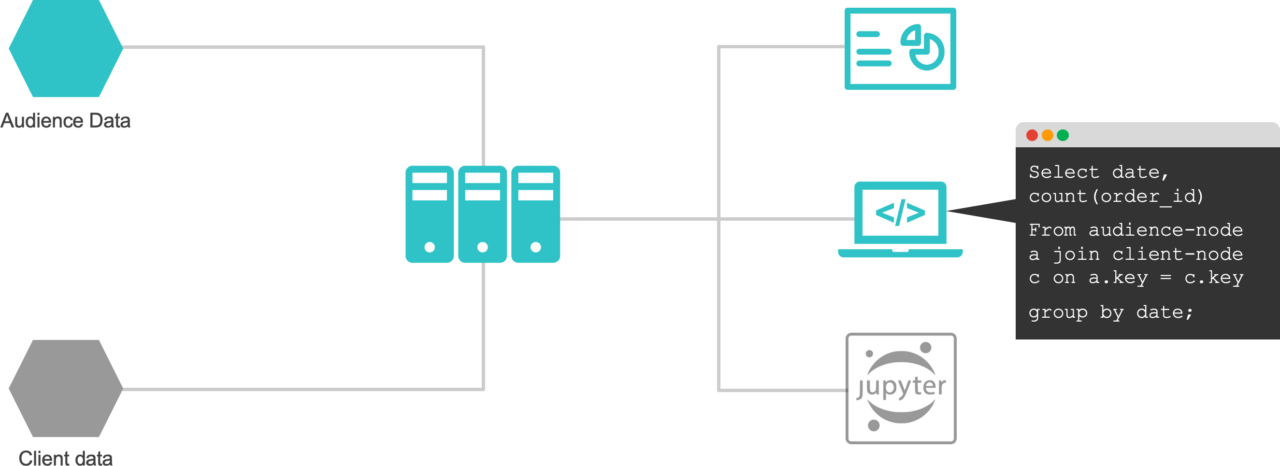
Neutral clean rooms allow querying partners’ and clients’ data without moving it from their environment (see Annalect’s AWS Clean room launch post, where we shared our experience).
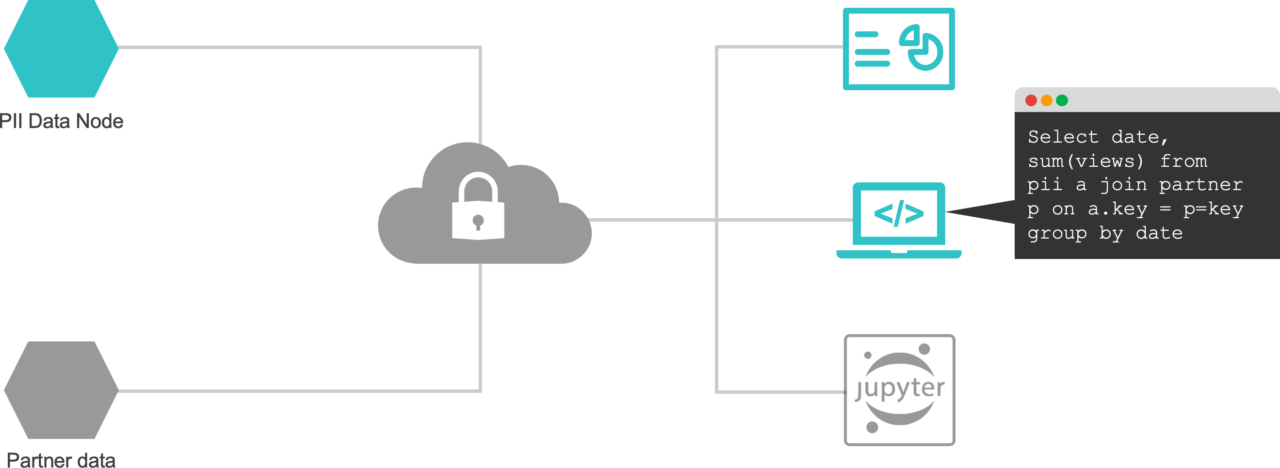
Both of these tools work across data nodes, whether they reside within one organization or across many, without unnecessary data movement. All of this happens in accordance with centralized governance and access principles, whether that means central, distributed or federated computing, or role-based access control down to the row-level.
The More-Secure, Less-Selfish Future of Data
When we embarked on this Data Mesh journey, our main objectives were liberation from rewrites, and data-sanity within our organization. Seamless, secure collaboration with our partners was a huge and unexpected bonus.
Organizations needn’t send data to each other to get work done. With new technology like clean rooms, we can work with client data without ever copying it or seeing sensitive consumer files. Similarly, working with partners like Demand Side Platforms, we can glean data insights without data dumps.
Amidst the ever-evolving landscapes of marketing and data, the ability to dynamically and securely work with our partners is crucial.
Final Thought
The Data mesh framework has been revolutionary in changing how people organize and manage data assets. However, we think one of its greatest advantages has not been explicity stated — the ability to do data work across organizations without physical data movement.